认识HTML
什么是HTML
HTML 是用来描述网页的一种语言。
- HTML 指的是超文本标记语言 (Hyper Text Markup Language)
- HTML 不是一种编程语言,而是一种标记语言 (markup language)
- 标记语言是一套标记标签 (markup tag)
- HTML 使用标记标签来描述网页
HTML 标签
HTML 标记标签通常被称为 HTML 标签 (HTML tag)。
- HTML 标签是由尖括号包围的关键词,比如
<html> - HTML 标签通常是成对出现的,比如
<b>和</b> - 标签对中的第一个标签是开始标签,第二个标签是结束标签
- 开始和结束标签也被称为开放标签和闭合标签
HTML 文档 = 网页
- HTML 文档描述网页
- HTML 文档包含 HTML 标签和纯文本
- HTML 文档也被称为网页
Web 浏览器的作用是读取 HTML 文档,并以网页的形式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容:1
2
3
4
5
6
7
8
9<html>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>
例子解释
<html>与</html>之间的文本描述网页<body>与</body>之间的文本是可见的页面内容<h1>与</h1>之间的文本被显示为标题<p>与</p>之间的文本被显示为段落
以下是常用标签及其含义
1 | <!DOCTYPE html> |
初始爬虫
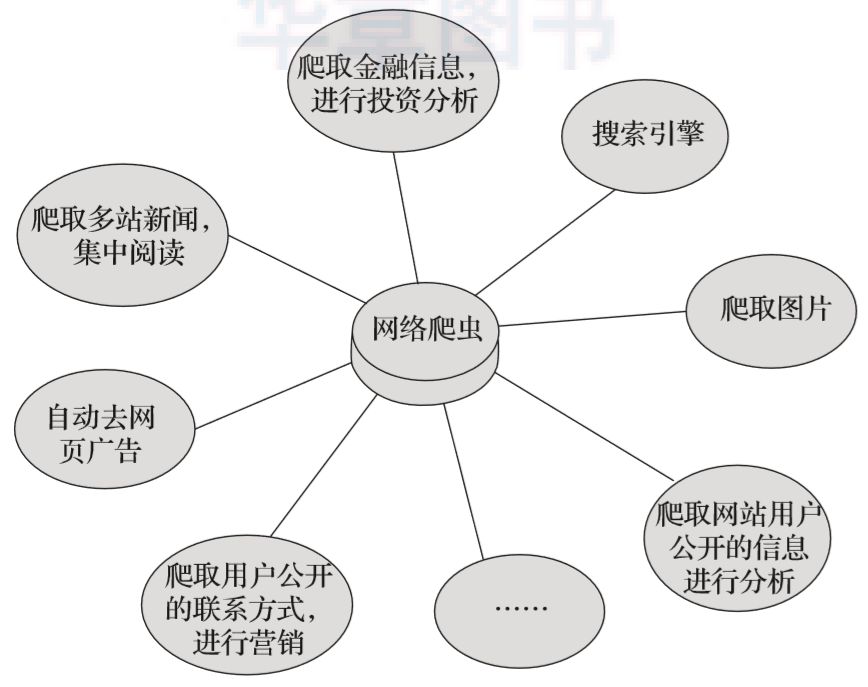
什么是爬虫
网络爬虫就行一只虫子,在互联网上爬啊爬,将获取的信息收集起来。
百度百科的定义为:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫的作用
现如今大数据时代已经到来,网络爬虫技术成为这个时代不可或缺的一部分,企业需要数据来分析用户行为,来分析自己产品的不足之处,来分析竞争对手的信息等等,但是这些的首要条件就是数据的采集。
爬虫协议
什么是爬虫协议?
爬虫协议就是你想用爬虫爬我的网站,那么你得听我的,哪些你能爬,哪些你不能爬。
怎么查看一个网站的爬虫协议呢,就在这个网站的域名后面加上robots.txt
比如说下面有:jd、百度、淘宝的爬虫协议
jd:https://www.jd.com/robots.txt
淘宝的:https://www.taobao.com/robots.txt
百度的:https://www.baidu.com/robots.txt
如果你要爬的网站域名加上robots.txt是404,那你就可以随心所欲的爬了。
不过就算爬虫协议里面写了,你也可以不遵守,但是也得注意一下,有的公司发现的话,会起诉的。比如说前几年著名的百度控诉360爬虫违反爬虫协议,索赔1亿元。
爬虫协议里面有这么几个字段:
User-agent:*
这个字段的意思是允许哪个引擎的爬虫获取数据
* 代表所有类型的爬虫都可以
Disallow:/admin/
这个字段代表爬虫不允许爬哪个路径下面的数据,如果是/的话,就代表所有的路径下面的数据都不能爬。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Sitemap: 网站地图 告诉爬虫这个页面是网站地图反爬虫
防止有人不遵守爬虫协议恶意爬取网站信息,于是,很多网站开始反网络爬虫,想方设法保护自己的内容。
他们根据ip访问频率,浏览网页速度,账户登录,输入验证码,flash封装,ajax混淆,js加密,图片,css混淆等五花八门的技术,来对反网络爬虫。
防的一方不惜工本,迫使抓的一方在考虑成本效益后放弃
抓的一方不惜工本,防的一方在考虑用户流失后放弃
#请求与响应
HTTP和HTTPS
HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法
HTTPS(HyperText Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Socket Layer安全套接层)主要用于web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
- HTTP的端口号为80
- HTTPS的端口号为443
http请求过程
打开一个网站的时候,过程是这样的客户端(浏览器)发送请求到服务端(你打开的网站所在的服务器),服务端接收到请求,处理,返回数据给客户端(浏览器),然后咱们在浏览器里面看到了数据。
明白了这个过程之后呢,咱们再来说http请求里面都包含了什么东西。
请求方式
主要有:GET/POST两种类型常用,另外还有HEAD/PUT/DELETE/OPTIONS
GET和POST的区别就是:请求的数据GET是在url中,POST则是存放在请求体里面。
GET:一般向服务器获取数据用get请求,get请求的数据都是放在url中的,实质上和post请求没有太大的区别,当然也可以用来向服务器发送数据。
POST:一般向服务器发送数据用post请求,post请求的数据放在请求体里。
HEAD:与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
PUT:向指定资源位置上传其最新内容。
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*’来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
DELETE:请求服务器删除Request-URI所标识的资源。
请求url
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三个部分组成:
第一部分是协议(或称为服务方式)。 http/https
第二部分是存有该资源的主机IP地址(有时也包括端口号)。 www.nnzhp.cn/192.168.1.1:8888
第三部分是主机资源的具体地址,如目录和文件名等。 /index
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
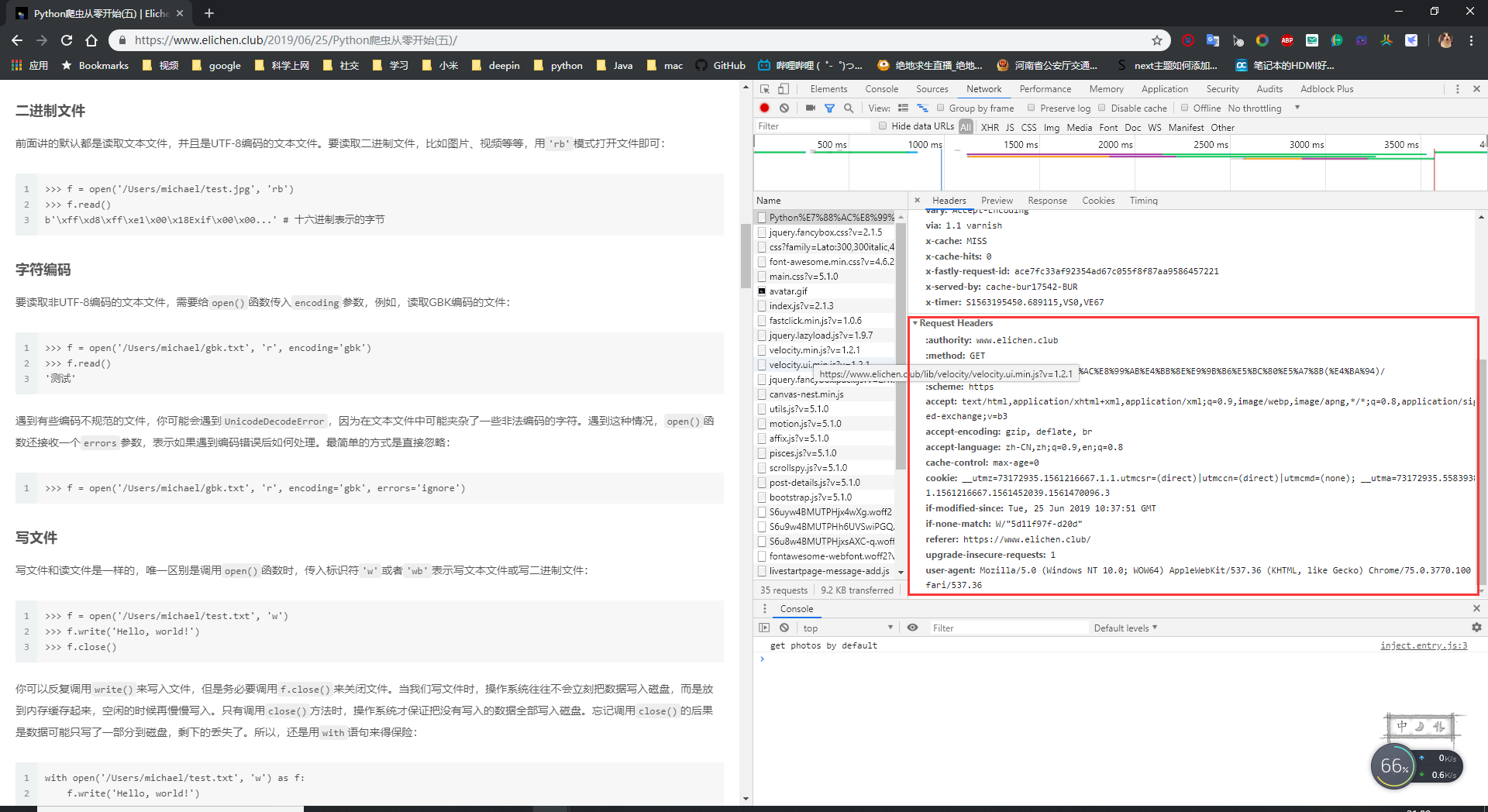
请求头
一个请求由两部分组成, 请求头和请求体。
包含请求时的头部信息,如User-Agent,Host,Cookies等信息,user-agent就是你请求用的是什么浏览器,host就是服务端的地址,还有很多信息,服务端是如何分辨你是用的什么浏览器,你的ip地址就是从请求头里面获取到的。下面就是在请求我博客的时候,发送的头信息。
请求体
请求体就是发送数据的时候,数据放在请求体里面。get请求是没有请求体的,从上面的截图也能看到,下面是没有这个请求体的。post请求才有请求体。下面的截图可以看到登陆的这个请求是一个post请求,登陆的账号密码就是放在请求体里面的。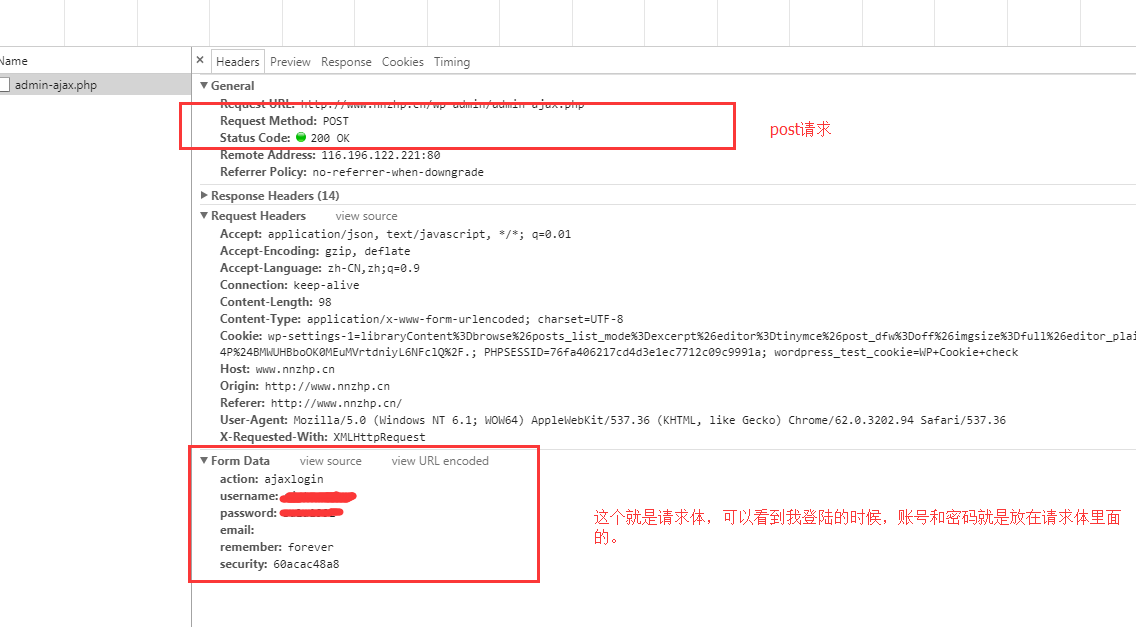
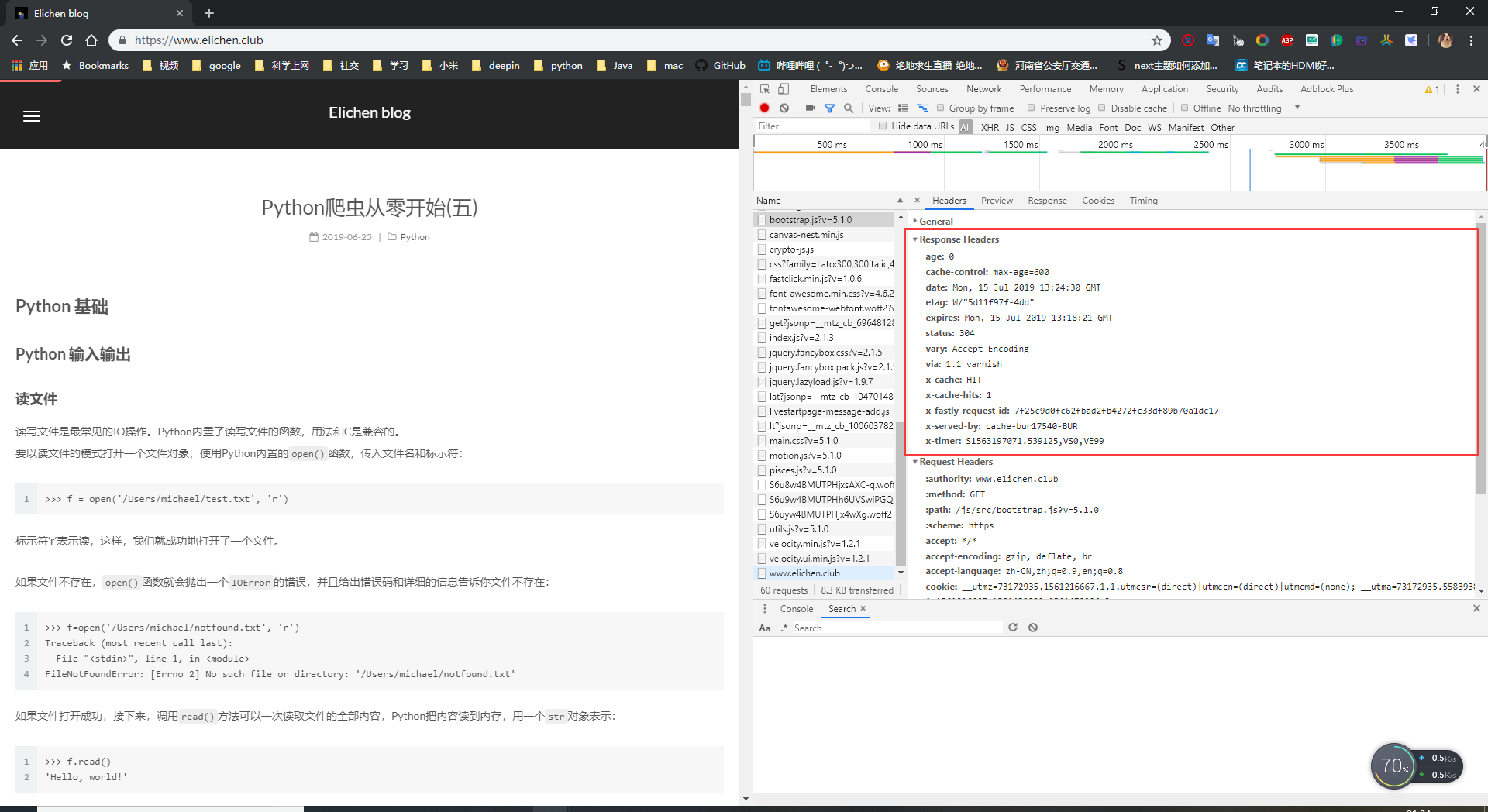
http响应
发送了请求,服务端要返回数据。这个就是响应,请求是你发出去的,响应是服务端返回给你的。
响应包含了2个部分,一个是响应头,一个是响应体。响应头里面包含了响应的状态码,返回数据的类型,类型的长度,服务器信息,Cookie信息等等。
响应体里面就是具体返回的数据了。
响应状态码
有很多响应状态,不同的状态码代表不同的状态,常见的状态码如:200代表成功,301跳转,404找不到页面,502服务端错误
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误 常见代码:
- 200 OK 请求成功
- 400 Bad Request 客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
- 403 Forbidden 服务器收到请求,但是拒绝提供服务
- 404 Not Found 请求资源不存在
- 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
- 301 目标暂时性转移
- 302 目标永久性转移
响应头、响应体
看下图~
代码示例
1 |
|

